





Ilmuwan Komputer asal Universitas Rice telah mendemonstrasikan perangkat lunak cerdas buatan (AI), yang berjalan pada prosesor komoditas dan melatih jaringan 15 kali lebih cepat dibandingkan platform berbasis prosesor grafis lainnya. GPU dikenal jauh lebih baik daripada kebanyakan CPU dalam hal AI Deep Neural Network (DNN), karena mereka memiliki lebih banyak unit eksekusi.
Deep Neural Networks (DNN) adalah bentuk kecerdasan buatan yang kuat dapat mengungguli manusia dalam beberapa tugas. Biasanya pelatihan ini merupakan rangkaian operasi perkalian matriks, beban kerja untuk unit pemrosesan grafis yang biayanya sekitar tiga kali lebih banyak daripada CPU.
Pelatihan DNN tidak diragukan lagi merupakan salah satu beban kerja komputasi intensif saat ini.Jadi jika ada pemrogram menginginkan kinerja pelatihan maksimum, mereka menggunakan GPU untuk beban kerja mereka. Hal ini karena lebih mudah untuk mencapai performa tinggi menggunakan komputasi GPU karena sebagian besar algoritma didasarkan pada perkalian matriks.
Anshumali Shrivastava selaku asisten profesor ilmu komputer di Brown School of Engineering Rice pada 8 April, dan rekannya telah mempresentasikan algoritma yang dapat mempercepat pelatihan DNN pada CPU modern yang mendukung AVX512 dan AVX512_BF16.
“Perusahaan telah menghabiskan jutaan dolar seminggu hanya untuk melatih dan menyesuaikan beban kerja AI mereka,” ujar Shrivastava.
Untuk membuktikan pendapat mereka, para ilmuwan menggunakan Sub-Linear Deep Learning Engine (SLIDE) berbasis C ++ OpenMP yang menggabungkan dengan paralelisme multi-core sederhana, dan dioptimalkan untuk AVX512 dan AVX512-bfloat16.
Mesin ini menggunakan Locality Sensitive Hashing (LSH) untuk mengoptimalkan persyaratan persyaratan kinerja komputasi. Bahkan tanpa modifikasi, bisa lebih cepat dalam melatih 200 juta jaringan neural dibandingkan implementasi TensorFlow yang dioptimalkan pada GPU Nvidia V100.
Hasil yang diperoleh dengan dataset Amazon-670K, WikiSLHTC-325K, dan Text8 memang sangat menjanjikan dengan mesin SLIDE yang dioptimalkan. Faktanya, bahkan prosesor Cascade Lake (CLX) yang diptimalkan bisa 2,55-11,6 kali lebih cepat daripada Tesla V100 milik Nvidia. Akselerasi berbasis tabel hash sudah mengungguli GPU, karena itu harus memanfaatkan inovasi untuk membawa SLIDE jauh lebih baik.
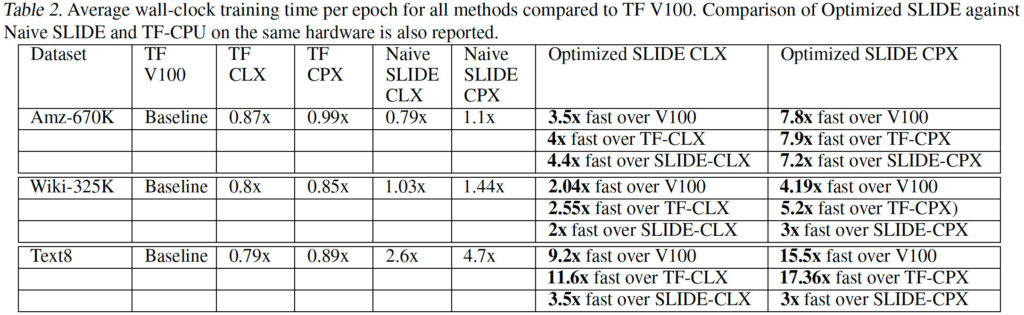
Dengan memanfaatkan daya dalam CPU modern dan melatih model AI empat hingga 15 kali lebih cepat daripada perangkat keras khusus terbaik. Tanpa ragu, algoritma DNN yang dioptimalkan untuk CPU yang mendukung AVX512 dan AVX512_BF16. Sangat penting untuk memanfaatkan semua kemampuan mereka.


















{kind=link}